The emergence of artificial intelligence is one of the most disruptive developments I have experienced in my 20-year career in tech.
I see AI as yet another evolution in how I work. It is transformational and here to stay. It's not unlike when responsive design emerged, and mobile-first development became the standard way of building websites or when cloud computing became the default choice for infrastructure.
Note: Many of the links referenced in this article are available on O’Reilly, which I access through my public library. If you can’t access these resources, check to see if your library offers access as well. They are not affiliate links and I get no commissions whatsoever.
Being Curious
My first exposure to AI and Machine Learning (ML) was with Natural Language Processing back in 2013. I remember writing a small Python script that used a now-abandoned package called Topia Term Extractor and Beautiful Soup to scrape keywords from my employer's competitors' web pages.
Later, I worked with Open Calais to tag editorial content in a CMS at a time when people thought structured data and RDFa would revolutionize how HTML documents were categorized.
Fast-forward to 2017 when I joined The Taunton Press and thought there would be opportunities to use sentiment analysis to use article comments as an editorial feedback mechanism and use collaborative filtering to act as a data point for related content recommendations.
By 2023, I started ramping up on Python. Though I had primarily used JavaScript, TypeScript, and PHP throughout my career, I wanted to add another general-purpose programming language to my toolbox. I chose Python because of its abundance of AI/ML libraries.
My final project before leaving The Taunton Press/Active Interest Media in 2024 was to iterate on the collaborative filtering idea. This time, I leveraged Google Analytics data and AWS Personalize to develop the next generation of the recommendations feature.
While job hunting in early 2024, I began using JetBrains AI as a coding assistant. It quickly became a part of my daily workflow and continues to be invaluable.
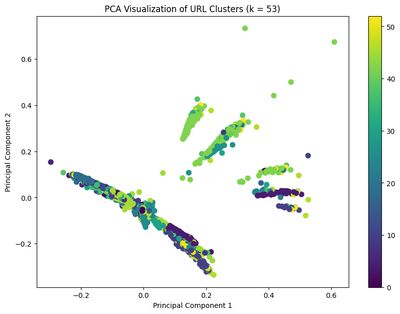
Finally, during my time at Flexion, I did a project on the 10x team that involved data analysis that used a machine learning algorithm (K-Means) for URL clustering.
How I Went About Learning What I Know
I came across a quote not too long ago that I found amusing:
There are two types of software practitioners, those that don't know anything about AI and those who pretend like they know more than they do.
First and foremost, I would certainly not consider myself an expert in AI. However, I have learned a lot about it over the last year as I've dedicated a significant portion of my professional development to educating myself on the topic. All of my past interactions with ML have been project-based learning, and I would encourage you to do the same with AI.
Having gone through hundreds of hours of courses in the last year, this is the learning path I would take to get up to speed.
Getting Started

I think the best place to start is Mozilla's AI Guide. This is foundational knowledge that should play a part in anyone's AI competency. There, you can expect to learn the following:
- The basics of AI
- Definitions of key terms (e.g. embeddings, inference, vectors, reinforcement learning from human feedback or RLHF)
- How to pick ML models
- LLM overview
- Running LLMs locally
There's also a great section that talks about the pros and cons, why people are concerned, and why people are excited about the capabilities of AI.
Local LLMs
One common misconception I had initially was that I needed a ton of money or a PhD to work with AI. In reality, there are some models that can be run locally, and that's how I suggest you get started experimenting. A working Python environment and Jupyter Notebook are all you really need to get started.
There are models on Hugging Face that can run on a laptop, like Mistral_7B, which won't run into disk space or processing power limitations. As the name implies, 7B means that it was trained on 7 billion parameters. For comparison, ChatGPT-4 is estimated to have 1.76 trillion parameters. Download a few models from Hugging Face, run them locally, and see what they can do.
The best overview I've seen on Hugging Face is Unlock Hugging Face: Simplify AI with Transformers, LLMs, RAG, Fine-Tuning. It walks you through the UI and provides some demos on how you can get your own project running.
There is also Applied Hugging Face, which covers how to run models in GitHub Codespaces. This gives you access to GPU hardware for training and fine-tuning purposes if you need to work in an environment with more compute resources.
Small Language Models and Llamafile is another interesting lesson because it explores how Rust is being used in LLMs and how a smaller model (2B parameters) can outperform a larger one (50B parameters) if the smaller model is provided with higher-quality training data. I think this underscores the fact that smaller models can be incredibly capable, more cost-effective, and easier to train. It's worth considering these trade-offs instead of automatically reaching for a larger or vendor-provided offering by default.
Understanding the Theory
If I could pick only one course about AI, Frank Kane's Machine Learning, Data Science and Generative AI with Python would be it. Not only is it the best course on AI that I have taken, it is one of the best courses I have ever taken on any CS topic.
This course provides an overview of many foundational ML concepts, explained in a clear manner. There is an excellent review of statistics, including regressions, Bayes' Theorem, distributions, and more. After the overview, the presenter introduces hands-on exercises and concepts like decision trees, boosting, recommendation engines, data pipelines, K-Means, and K-Nearest Neighbors. Other concepts like LLMs, Retrieval Augmented Generation (RAG), Transformers, and Self-Attention Based Neural Networks are also covered.
The course also includes a lesson on how you might deploy an ML solution to production in AWS or a similar cloud provider.
One of the critical insights from the course is that training and deployment are two independent tasks. You can train the models offline or on a separate workload from the workload that serves the output to the end user.
AI Engineering provides another look at some of the theory behind AI. There is a great chapter in this book on how to evaluate models and understand language modeling metrics. Additionally, there is practical advice on when to fine-tune and tips for prompt engineering. I've only started this book, but I'm enjoying it so far.
System Design and Deployment
Once you get your bearings, it's likely you'll move toward deploying a system to production. Although Frank Kane's course includes a brief overview of how to deploy an AI solution, this is a much deeper topic.
There are lots of choices to be made along the way, and this presentation by Yujian Tang explores different options for vector databases and frameworks like Langchain. It's only 30 minutes, and it's packed with information. Tang also discusses some of the challenges of deploying an LLM. It's a great overview of the various moving pieces involved in running a production LLM app.
LLMs in Production has a valuable chapter on how to build a platform for LLMs. There is also an interesting chapter about running a model on a Raspberry Pi, which demonstrates that some models can run on modest hardware, especially if you're deliberate about optimizing them (disclosure: I work at the same company as one of the authors).
If you recall the section in the Small Language Models course above where the presenter talked about MLOps, I think this is an area that could be an exciting but overlooked field for delivering AI solutions in production. The presenter mentioned a "rule of 25%" that suggests allocating 25% of your company's time to DevOps and Kaizen, 25% to Data, 25% to Models, and 25% to Business. In this approach, you apply the same type of thinking and sophistication as you would any other app. Some of the critical points include:
DevOps
- Are we making things more efficient?
- Are we improving practices each week?
- What is slowing us down?
- Are we in a state of waste (Muda)?
Data
- Are we operationalizing the data ingestion and cleaning?
- Do we have clean data?
- What are the risks in the system?
Models
- Addressing bias
- Training methods
- Cost efficacy
Business Case
- Are we solving the problem the company needs?
If you want to dig deeper, there is a book called Practical MLOps that delves further into this topic.
Conclusion
Diving into AI doesn't require mastery or a PhD. It requires a willingness to learn, experiment, and keep pace with the evolving landscape of technology. There are new developments every day, but by giving yourself a gradual on-ramp, diving into AI can become a less daunting task than trying to learn everything at once. By starting with foundational knowledge, rolling up your sleeves to experiment with local models, and then layering on theoretical and practical approaches, the journey into AI becomes both approachable and rewarding.
Stay curious, stay hands-on, and remember that the real goal isn't to know everything; it's to know enough to move forward effectively.